
Andrej Karpathy posted a gist last week. Five thousand stars in seven days. The comment section is a parade of CLI tools, Obsidian plugins, Claude Code skills, research frameworks, knowledge graphs. Everyone’s version of the same pattern, shipped in the week since the post went up. I read the gist on a Saturday morning, and I reread it three times before I believed the dates.
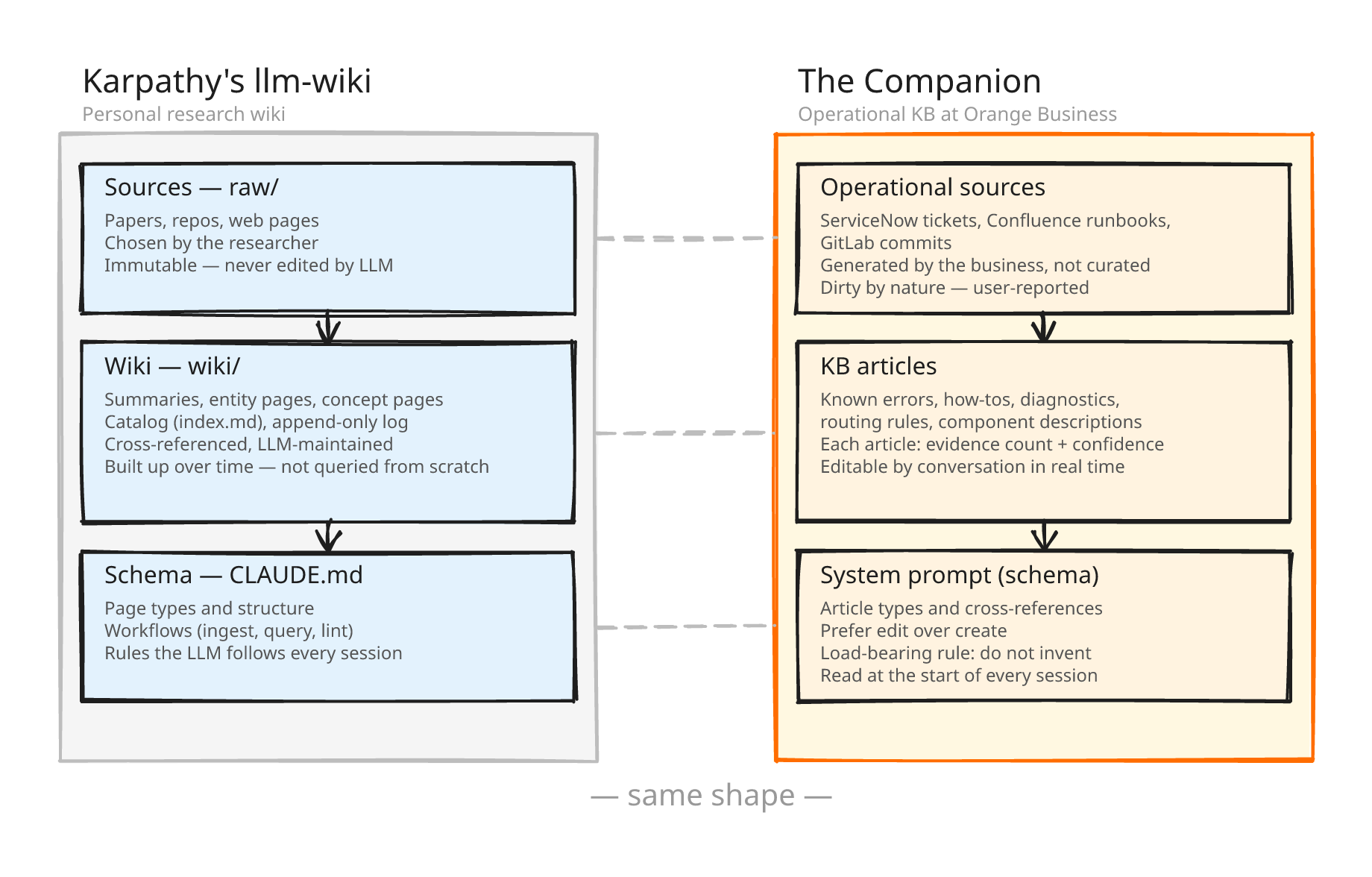
Three months ago, at Orange Business, I started building what Karpathy describes. Three layers, the same discipline, the same idea of a markdown knowledge base that the LLM reads, writes, and maintains for itself, with the schema living in a prompt the model reads on every run.
I didn’t know it had a name. I didn’t know dozens of other people were reaching for the same shape in the same quarter. I was just trying to solve a problem in front of me: how an AI companion should help a support engineer resolve a production incident at 3 AM. The shape that came out the other end is, almost line for line, what Karpathy published.
Here’s what that looks like from the inside.
Where it lives
Orange’s 2026–2030 strategic plan (“Trust the Future”) commits to a new industrial model for operations, built on AI to make networks more effective and more resilient. That commitment has to land somewhere concrete: in code, in front of real users, with real incidents being resolved.
I’m an AI engineer at Orange Business. I build agentic AI products for operational teams. The one I want to walk you through (let’s call it the Companion) is an AI companion for L1, L2, and L3 support engineers resolving production incidents. The shape it ended up having is the same shape Karpathy described, and I didn’t get there by copying him.
What Karpathy described
Read the gist. I’d rather you hear it from him than from me. But here it is in one breath.
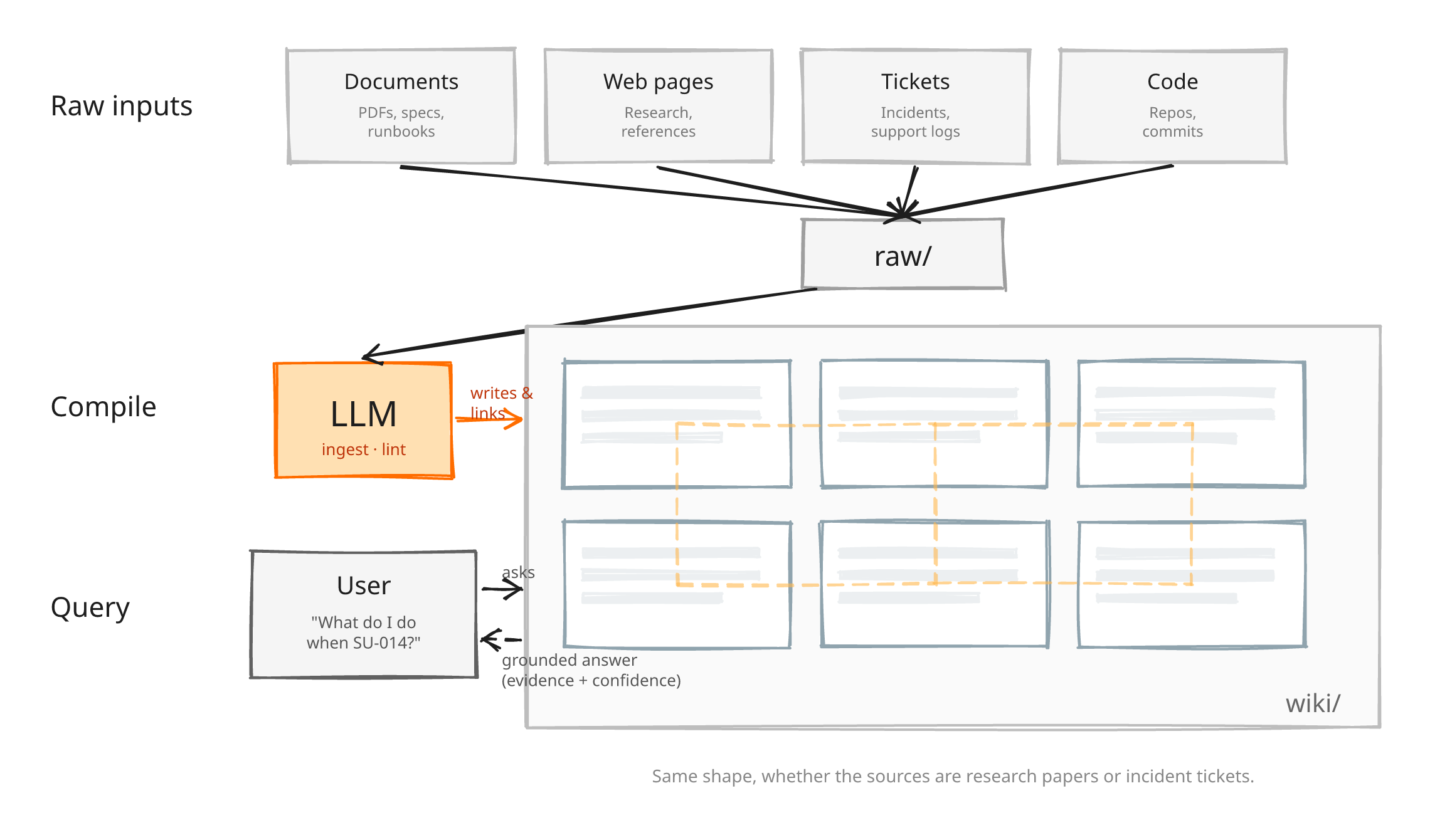
The system has three layers. A folder of immutable source material. A folder of markdown pages the LLM writes and maintains (summaries, entity pages, concept pages, a catalog, an append-only history). And a schema document that tells the LLM how the wiki is organized, what each kind of page should contain, and what workflows to follow.
On top of that sit three operations.
- Ingest: you drop a source into the raw folder, tell the LLM to process it, it reads the source, discusses it with you, writes a summary page, updates entity and concept pages across the wiki, appends to the log. A single source might touch ten to fifteen pages.
- Query: the LLM reads the catalog first, then pulls the pages it needs.
- Lint: periodically, you ask the LLM to health-check the wiki for contradictions, stale claims, orphan pages.
Karpathy’s framing of why this is not RAG is the line I’d put on a t-shirt:
Ask a subtle question that requires synthesizing five documents, and the LLM has to find and piece together the relevant fragments every time. Nothing is built up.
The wiki is built up. RAG isn’t.
All of this happens inside a single conversation with a single agent. Karpathy recommends Claude Code (or Codex, or OpenCode) as the host. One chat, one agent, one set of filesystem operations, reading and writing the same wiki in the same session. The comment section is full of people building variations on exactly that.
What I was already building
The Companion is an AI companion for Orange Business support engineers. A support engineer opens an incident, asks the Companion “what do we do when the export pipeline fails with error SU-014,” and the Companion reads its knowledge base and answers.
When the engineer resolves the ticket (maybe they discover a new workaround, maybe the fix updates an existing article, maybe a whole new known-error page needs to exist), they tell the Companion in the same conversation: “update the SU-014 article with the rollback command we just ran.”
Same agent, same chat window, reading and writing on the same surface, driven by natural language from a tired human who wants to get home. One knowledge base, editable by conversation.
The schema, the thing Karpathy puts in his CLAUDE.md, lives in a system prompt the Companion reads at the start of every session. It tells the model what kinds of articles the KB contains (known errors, how-tos, diagnostic trees, routing rules, component descriptions, operational patterns), how articles cross-reference each other, and how to prefer editing an existing article over creating a new one.
And the single most important rule in the whole prompt:
The Companion cannot invent anything. Every fact in every article has to come from a real incident.
One sentence of prose in a schema file. The KB is going to be consumed by people who run what the Companion tells them to run, so this rule matters more than any other part of the prompt.
Two design choices from the same schema do most of the trust work.
Every article declares its evidence
At the top of every page, the Companion writes down how many incidents the article was grounded in (evidence count), and how certain it was when it wrote it (confidence). When a support engineer asks a question, the answer comes back with that context attached: “this article is grounded in 43 resolved incidents, high confidence” versus “2 incidents, low confidence.” With production down and a decision under pressure, that distinction matters.
It’s also the concrete answer to a question I saw asked several times in Karpathy’s comment section: how do you track provenance, handle contradictions, know when to invalidate memory? Evidence and confidence, declared per article, written by the model that wrote the article. A small, prompt-level trick that’s been quietly doing the job for three months.
The grounding rule lives in the prompt
No retrieval filter, no verification pass, no external ground-truth check. The rule lives in the schema, the model reads the schema at the start of every session, and every article it writes is grounded in incidents that are in the same context window as the schema telling it not to drift.
That sounds fragile, and it is. We have caught hallucinations. We have found bugs. The Companion has written KB articles that slipped something in that wasn’t in the source tickets, and we’ve had to go back and fix them. In the adversarial case the rule is even weaker: a prompt-injected ticket, a drift in the distribution of source material, and the schema alone isn’t going to hold.
What the rule does well is make those failures visible. Every article declares its evidence, every claim points at a source ticket, and when something goes wrong it shows up on inspection. The design is a WIP and we know it. What it is not is a blind-trust system. The reason we trust it at all is that the failures have so far been the kind you can see.
What’s specific to operational work
Four things about the Companion are specific to where it lives (L1/L2/L3 support) and they shaped the implementation.
The sources are operational, not curated
Karpathy’s raw material is what he chose to read: papers, repos, web pages he’s studying. Ours is generated as a byproduct of running a business: resolved incidents in ServiceNow, runbook pages in Confluence, commits in GitLab.
Nobody “chooses” to read an incident ticket. It happens because something broke. The Companion’s KB compounds knowledge the team already produced doing its job, not knowledge the team went out and acquired.
History is inherited from the substrate
Karpathy’s gist introduces an append-only log to give the wiki a chronological audit trail. We didn’t need to invent it. Confluence already does page history, ServiceNow already does ticket audit trails, GitLab already does commits.
The KB sits on top of enterprise systems that know who wrote what, when, and as part of which ticket. Karpathy’s log is a clever workaround for a plain-markdown-folder limitation we don’t have. We got versioning for free, because we chose to live inside the substrate our users were already living in.
Multi-tenant by default
Karpathy’s wiki is personal. It’s his wiki about his reading. The Companion is one system serving many customer teams, and it cannot leak across them.
Access control comes from the backing systems, not from a layer we built on top. Same pattern as history: we get the governance we need because we live where the governance already lives.
The sources are dirty
This is the one Karpathy’s gist doesn’t have to deal with. His raw material is what he chose to read: clean, intentional, curated. Ours is incident tickets, written by users under pressure. Users describe what they think happened, not what actually happened.
When someone misunderstands how a system works and files a ticket based on that misunderstanding, the Companion ingests that ticket and writes it into the KB. Now the support team’s documentation reflects the user’s wrong mental model.
The “do not invent” rule protects against hallucination, but it doesn’t protect against the source material being wrong in the first place. That’s a harder problem, and we don’t have a clean answer for it yet.
None of these are contrasts with Karpathy’s gist. The gist is deliberately abstract. It’s an idea file, and he explicitly invites you to instantiate it for your domain. This is how ours turned out.
A personal wiki sitting on a laptop is one version of it. The Companion sitting on top of Confluence, ServiceNow, and GitLab inside Orange Business is another. Same shape, different substrate.
What I’m adopting
Two things from Karpathy’s gist I don’t yet have.
A periodic health check
Right now the Companion edits the KB every time a support engineer asks it to. Over weeks, two engineers on two different teams might write two articles that quietly disagree with each other, and nothing notices. Karpathy’s framing (the same LLM that wrote the wiki runs a health-check over it on a schedule) is better than what I have. It’s cheap, it’s mostly a prompt, and I can ship it next week.
A catalog read as the first move
The Companion currently goes looking for relevant pages when answering a question. It searches, skims, reads what looks promising. Karpathy’s pattern is cleaner: read the catalog first, let the table of contents decide which pages to pull. The catalog also doubles as the landing page of the human-facing docs site we publish alongside the LLM-facing KB. Two wins for one file.
Neither of these requires changing the core loop. Both sit in the schema layer plus one naming convention. The reason I hadn’t added them is that I wasn’t looking for them. Karpathy’s gist showed me they were there.
Where this goes
The wiki pattern works, and people are arriving at it from different angles. Dozens of implementations have surfaced in Karpathy’s comment section in the week since the gist went up, built by people who’ve never met, using the same primitives to solve different problems.
RAG was a compromise. It existed because context windows were small, models couldn’t be trusted to edit their own files, and we didn’t have filesystem-shaped tools as a first-class primitive. All three of those constraints broke in 2025. The wiki-shaped answer is the natural one now.
But the interesting problem is not the wiki. It’s what the wiki makes visible.
When the Companion ingests hundreds of tickets and builds a knowledge base from them, it also accumulates a map of how users understand the systems they’re using. Every misunderstanding that makes it into a ticket, and then into a KB article, carries information about where users get confused.
If users keep describing the same system the wrong way, that’s not a documentation problem. It’s a product problem, or a training problem, or an experience problem. And the Companion is sitting on that data.
The thing I want to build next is the system that reads the wiki and tells a product owner: your users don’t understand how this works, and here’s exactly where they get lost. That’s true for applications, but also for workplace tools, internal platforms, anything people interact with and quietly misunderstand.
The KB can be used as a sensor, not only as a reference.
That’s the version of this pattern I haven’t seen in Karpathy’s comment section yet.
If you’re building something like this too, for research, for ops, or for a team at a company that happens to have a lot of Confluence pages and a lot of tired support engineers, I’d like to compare notes.